| | |
| | |
| Spanish Expressive Voices
Corpus Description | |



|
- Acquisition of six emotions: happiness,
cold/hot anger, surprise,
sadness, disgust, fear plus
neutral reference.
- Multi speaker/gender information: 1 male and 1 female.
- 'Close' talk speech purpose is emotional
speech synthesis and emotional patterns analysis
related to emotion identification tasks.
- 'Far' talk speech purpose is to evaluate
the impact of affective speech capture in more
realistic conditions (with microphones placed far
away from the speakers), also in tasks related to
speech recognition and emotion identification.
- Video capture is allowing : Research on
emotion detection using visual information, face tracking studies.
Possibility of study specific head, body or arms behaviour that could
be related to features such as emotion intensity level or give
relevant information of each emotion played.
- Audio-visual sensor fusion for emotion identification and
even affective speech recognition are devised as potential
applications of this corpus.
- Emotional Level Corpus
15 reference sentences of
SESII-A corpus were played by actors 4 times,
incrementing gradually the emotional level
(neutral, low, medium and high level).
- Diphone concatenation synthesis corpus
LOGATOMOS corpus is made of 570 logatomos within the main Spanish
Di-phone distribution is covered. They were grouped into 114
utterances in order to provide the performance of the actors. Pauses
between words were requested to them in the performance in order to be
recorded as in an isolated way.
This corpus allows studying the impact and the
viability of communicate affective content through
voice by no semantic sense words. New voices for
limited domain expressive synthesizers based on
concatenation synthesis would be built.
- Unit Selection synthesis corpus
QUIJOTE is a corpus made of 100 utterances
selected from the 1st part of the book "Don
Quijote de la Mancha" and that respects the
allophonic distribution of the book. This wide
range of allophonic units allows synthesis by
unit selection technique.
- Prosody Modeling
In SESII-B corpus , hot anger was additionally
considered in order to evaluated different kinds
of anger. The 4 original paragraphs in SES has
been split into 84 sentences. PROSODIA corpus
is made of 376 utterances divided into 5
sets.
The main purpose of this corpus is to
include rich prosody aspects that makes possible
the study of prosody in speeches, interviews,
short dialogues or question-answering
situations.
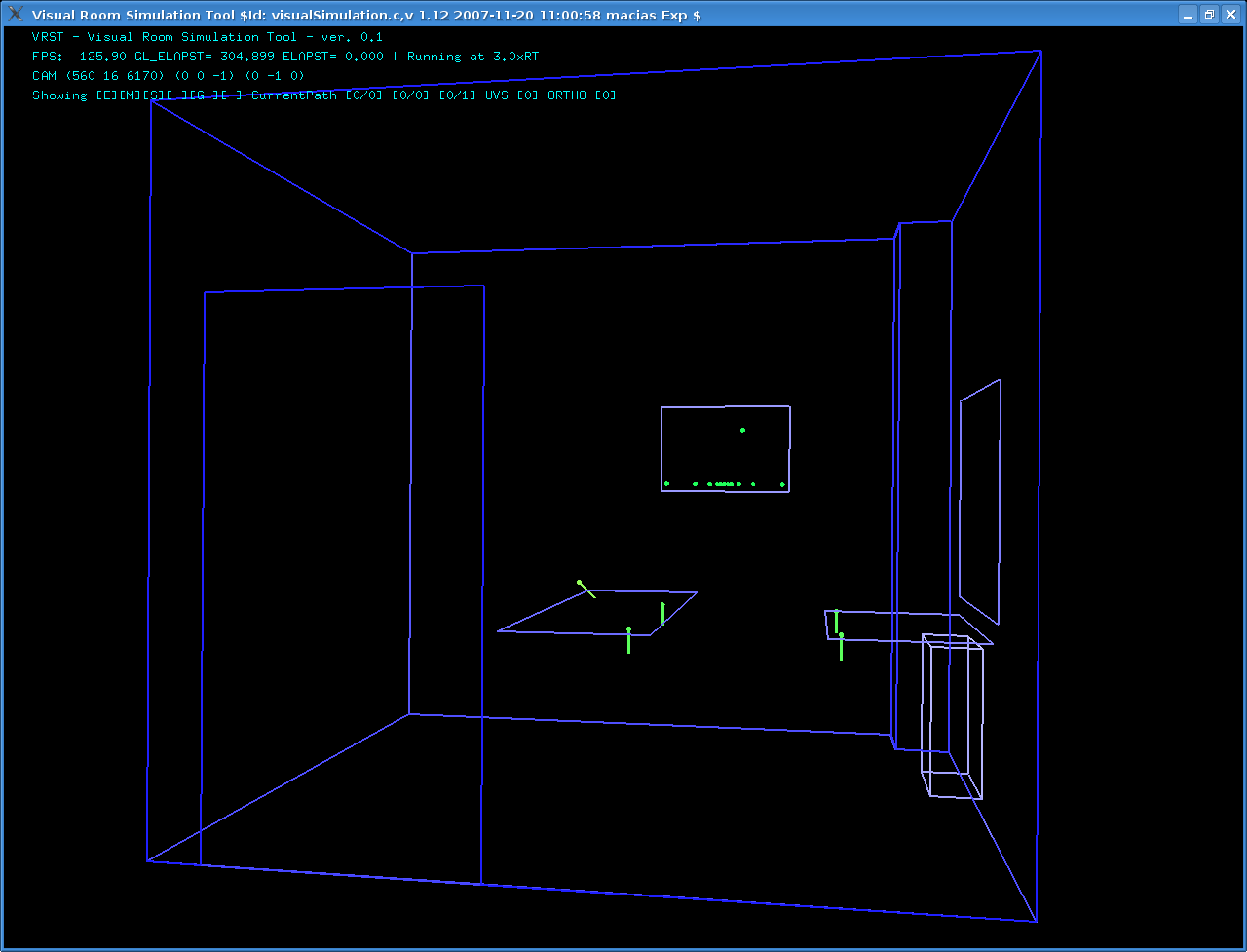
- A linear harmonically spaced array composed of 12 microphones placed on the left wall.
A roughly squared microphone array composed of 4 microphones placed on two tables in front of the speaker.
|
 |
- Utterances were recorded using 720x576 resolution and 25 frames per second.
Video data has been aligned and linked to speech and text data, providing a fully-labeled multimedia database.
|
|
Phonetic and Prosodic Labeling
- Phonetically labeled using HTK
software in an automatic way.
- In addition to this, 5% of each sub-corpus in
SEV has been manually labeled, providing reference
data for studies on rhythm analysis or on the
influence of the emotional state on automatic
phonetic segmentation systems.
- EGG signal has also been automatically
pitch-marked and, for intonation analysis, the same
5% of each sub-corpus has been manually revised too.
- Close talk speech of SESII-B, QUIJOTE and
PROSODIA (3890 utterances) has been evaluated using
a web interface.
- 6 evaluators for each voice participated in the
evaluation. They could hear each utterance as many times they need.
Evaluators were asked for:
- the emotion played on each utterance
- the emotional level (choosing between very low, low, normal, high or very high).
- Each utterance was evaluated at least by 2 people. The Pearson coefficient of identification rates between the evaluators was 98%.
- A kappa factor of 100% was used in the validation. 89.6% of actress utterances and 84.3% of actor utterances were validated.
- 60% of utterances were labeled at least as a high level utterance.
- Whole database has been evaluated by an objective emotion identification experiment
- Based on PLP speech features and its dynamic parameters.
- 95% identification rate (average for both speakers) was obtained.
- A 99% Pearson coefficient was obtained between the perceptual and objective evaluation.
- The mean square error between the confusion matrices of both experiments is less than 5%.
|
|